
Optymalizacja pod AI w 2026 - na co zwrócić uwagę?
Optymalizacja pod AI, szerzej określana jako GEO (Generative Engine Optimization), staje się dziś jednym z ważniejszych kierunków w SEO. Systemy generatywne skracają drogę użytkownika do odpowiedzi, a Google AI Overviews i AI Mode działają jako warstwa odpowiedzi z linkami wspierającymi, nie tylko jako klasyczna lista wyników. Google zaznacza przy tym, że nie ma osobnych wymagań technicznych ani „specjalnej optymalizacji” dla AI Overviews i AI Mode. Fundamenty pozostają te same: indeksowalność, jakość, crawlability, dostępność fragmentu i people-first content. Zmienia się jednak sposób oceny skuteczności. Poza pozycją i CTR warto monitorować cytowania, wzmianki, udział marki w odpowiedziach oraz stabilność obecności między modelami.
Największa zmiana dotyczy kliknięć. W klasycznym SEO użytkownik wybierał wynik z listy. W GEO coraz częściej otrzymuje syntetyczną odpowiedź, a kliknięcie staje się opcjonalne. SparkToro i Datos wskazywali w badaniu zero-click, że na 1000 wyszukiwań Google w USA tylko 374 kliknięcia trafiały do otwartego webu. Nowsze analizy pokazują też, że wpływ AI Overviews zależy od typu zapytania i od tego, czy marka pojawia się w cytowaniach. W badaniu Seer Interactive na 3119 frazach i 25,1 mln organicznych impresji zapytania z AI Overview, w których marka nie była cytowana, miały organiczny CTR 0,52%, a zapytania z cytowaniem 0,70%. Nie dowodzi to prostej przyczynowości, ale dobrze pokazuje kierunek: sama pozycja organiczna nie wystarcza, jeśli domena nie trafia do panelu odpowiedzi.
Jakość ponad ilość
Rosną też wymagania wobec treści, choć odpowiedzi modeli nadal nie są w pełni niezawodne. Problemem jest nie tylko „halucynacja”, czyli zmyślona odpowiedź, ale również błędna atrybucja, niepełne pokrycie źródeł oraz niespójność między streszczeniem a cytowaną stroną. Stanfordzkie badanie generatywnych wyszukiwarek wykazało, że średnio tylko 51,5% wygenerowanych zdań było w pełni wspartych cytowaniami, a 74,5% cytowań wspierało powiązane zdanie. Z kolei prace nad detekcją halucynacji pokazują, że problem pozostaje systemowy: modele mogą generować płynne i wiarygodnie brzmiące, ale niepoprawne odpowiedzi. Nature opisuje to jako potrzebę wykrywania konfabulacji i niepewności w odpowiedziach LLM („detecting hallucinations in LLMs”). To zwiększa ryzyko błędnych parafraz i niepoprawnej atrybucji, zwłaszcza gdy treści są niespójne, zduplikowane, pozbawione źródeł albo trudne do segmentowania przez LLM (Large Language Model).
„Raters consider the quality of the webpage using criteria that we call E-E-A-T: Experience, Expertise, Authoritativeness and Trust.” - Search Quality Rater Guidelines
Google potwierdza, że E-E-A-T to kluczowa koncepcja oceny jakości treści w Search Quality Rater Guidelines. W praktyce oznacza to konieczność konsekwentnego budowania sygnałów autorstwa, źródeł i rzetelności w całym serwisie. W kontekście GEO E-E-A-T warto traktować praktycznie: nie jako dekoracyjny box autora, lecz jako zestaw dowodów, które model może rozpoznać, porównać i przytoczyć. Liczą się m.in. autor, data aktualizacji, metodologia, źródło danych, ograniczenia, cytowane badania, doświadczenie własne oraz zewnętrzne potwierdzenia encji marki.
Jeden temat nie wystarczy
Problem można opisać dwutorowo. Z jednej strony maleje udział kliknięć, bo wyszukiwarki i asystenci, tacy jak Google, Microsoft Bing, Copilot, Perplexity czy ChatGPT, agregują odpowiedzi. Z drugiej strony rośnie wrażliwość LLM na strukturę, spójność i kontekst semantyczny. Google wskazuje, że AI Overviews i AI Mode mogą używać techniki „query fan-out”, czyli wykonywania wielu powiązanych wyszukiwań po subtematach i źródłach danych. Oznacza to, że pojedyncza fraza główna nie opisuje już całego pola konkurencji. Trzeba pokrywać klastry pytań, warianty intencji, porównania, definicje, przykłady, dane i źródła potwierdzające.
Optymalizacja techniczna jest niezwykle ważna
W takim środowisku optymalizacja pod AI obejmuje m.in. precyzyjną architekturę informacji, wdrożenie Schema.org i danych strukturalnych, jednoznaczne nagłówki, klarowne akapity (chunking), sygnały E-E-A-T oraz kontrolę duplikacji i kanonikalizacji. Trzeba jednak unikać uproszczenia, że „schema gwarantuje cytowanie”. Google jasno zaznacza, że poprawne dane strukturalne mogą kwalifikować stronę do rich results, ale nie gwarantują ich wyświetlenia. Ich wartość w GEO polega przede wszystkim na ułatwieniu zrozumienia encji, relacji, typu treści i głównego obiektu strony.
Niepożądane symptomy
Najpierw warto rozpoznać objawy, które najczęściej pojawiają się w audytach pod AI.
Spadek udziału kliknięć z fraz informacyjnych przy stabilnych pozycjach, zwłaszcza gdy SERP zawiera AI Overviews, Featured Snippet, PAA lub inne moduły answer-first.
Niska albo zanikająca liczba cytowań domeny w panelach odpowiedzi, takich jak Bing Copilot, Google AI Overviews, Perplexity czy ChatGPT Search, mimo obecności w TOP10 organic.
Wzrost kosztów crawlowania przez boty AI i nieznanych agentów. Dlatego warto analizować logi oraz rozróżniać klasy crawlerów, np. OpenAI opisuje osobno OAI-SearchBot, GPTBot i user-triggered fetchery, a Google udostępnia kontrolę przez Google-Extended w robots.txt.
Rozjazdy faktograficzne w odpowiedziach modeli względem treści źródłowej: halucynacje, błędne parafrazy, niepełne cytowania i przypisywanie danych do niewłaściwej marki.
Kanibalizacja tematów między podstronami, wskazująca na problemy z kanonikami, duplikacją, niespójną architekturą informacji albo brakiem strony nadrzędnej dla encji.
Duże wahania CTR w rich results przy braku danych strukturalnych, błędach walidacji albo oznaczeniu danych niewidocznych dla użytkownika.
Brak „citable passages”, czyli krótkich, samodzielnych fragmentów, które zawierają odpowiedź, kontekst, liczbę lub źródło i mogą być bezpiecznie przytoczone przez model.
Niespójność między treścią HTML, danymi strukturalnymi, grafikami, tabelami, PDF-ami i feedami produktowymi, przez którą modelom trudniej ustalić jedną wersję prawdy.
Źródła tych symptomów są zwykle techniczno-semantyczne. Niespójne kanonikale wzmacniają sprzeczne sygnały, brak precyzyjnych nagłówków utrudnia wydzielenie cytowalnych zdań, a duplikaty treści rozbijają autorytet tematyczny między kilka adresów URL. W GEO szczególnie groźne są strony „prawie poprawne”: indeksowalne, ale niejednoznaczne; obszerne, ale bez źródeł; zoptymalizowane pod frazę, ale bez answer readiness.
Wdrożenie danych strukturalnych i jasnej architektury informacji zwiększa czytelność treści dla systemów wyszukiwania, ale nie powinno być traktowane jako samodzielna dźwignia GEO. Minimalny zestaw dla treści eksperckich to zwykle Article lub BlogPosting, Person, Organization, WebPage, BreadcrumbList oraz FAQPage tam, gdzie FAQ jest realnie widoczne dla użytkownika. Warto też zadbać o właściwości opisujące autora, datę modyfikacji, źródła i główną encję. Google wskazuje, że używa structured data do rozumienia zawartości strony i obiektów opisanych w treści, a Schema.org definiuje m.in. Article jako typ z właściwościami autora, dat i atrybucji oraz FAQPage jako stronę z pytaniami i odpowiedziami.
Autorytet autora
W praktyce spójne sygnały autorstwa, takie jak bio, afilia, profil eksperta, ORCID lub inny zewnętrzny identyfikator, a także konsekwentne podawanie źródeł, metryk i metadanych licencyjnych w treści (rights, license, attribution), zwiększają szanse prawidłowej atrybucji przez systemy AI. Najważniejsze jest jednak to, aby źródła były przypięte do konkretnych twierdzeń, a nie tylko zebrane na końcu artykułu. Dla LLM fragment „według badania X spadek wyniósł Y%” jest znacznie łatwiejszy do użycia niż ogólny akapit z listą materiałów.
Równolegle warto inwestować w treści oparte na wiarygodnych danych pierwotnych. Systemy retrieval i generatywne odpowiedzi premiują materiały, które wnoszą information gain: oryginalne dane, benchmarki, porównania, własne obserwacje, metodykę i interpretację. Akademicki paper o GEO wskazał, że metody takie jak dodanie cytowań, statystyk i bardziej autorytatywnego języka mogą zwiększać widoczność w generatywnych odpowiedziach nawet do 40% w badanym benchmarku, choć efekty zależą od domeny, typu zapytań i konkretnego silnika. Dlatego GEO nie polega na „upiększeniu” tekstu, lecz na zwiększeniu jego użyteczności jako źródła odpowiedzi.
Z perspektywy dostarczalności treści do ekosystemów AI krytyczna jest wydajność serwisu i stan sygnałów indeksacyjnych. Strona, która blokuje crawlowanie, ma chaotyczne canonicale, zbyt agresywne renderowanie JS albo nieudostępnia snippetów, może być widoczna dla użytkownika, ale słaba jako źródło dla systemów answer-first. Google wyjaśnia, że aby strona mogła pojawić się jako link wspierający w AI Overviews lub AI Mode, musi być zaindeksowana i kwalifikować się do wyświetlenia w Search ze snippetem. Dodatkowo robots meta i X-Robots-Tag pozwalają kontrolować indeksowanie oraz sposób serwowania treści w wynikach, co ma znaczenie przy noindex, nosnippet, max-snippet i data-nosnippet.
Dowody to potwierdzają
Dowody z naszych wdrożeń pokazują, które taktyki mają największą trakcję. Wdrożenie znaczników FAQPage tam, gdzie FAQ było widoczne w treści, ujednolicenie H2/H3 i dodanie linków do źródeł wygenerowało +22% udziału cytowań w odpowiedziach Bing Copilot.
W innym przypadku uporządkowanie canonicali i usunięcie duplikatów obniżyło liczbę błędnych parafraz przez modele o ~50% według wewnętrznego monitoringu odpowiedzi. Z kolei artykuły z danymi strukturalnymi, aktualną datą modyfikacji, tabelą źródeł i krótkim podsumowaniem odpowiedzi osiągnęły +15% CTR z rich results i były o +12% częściej wzmiankowane w AI Overviews.
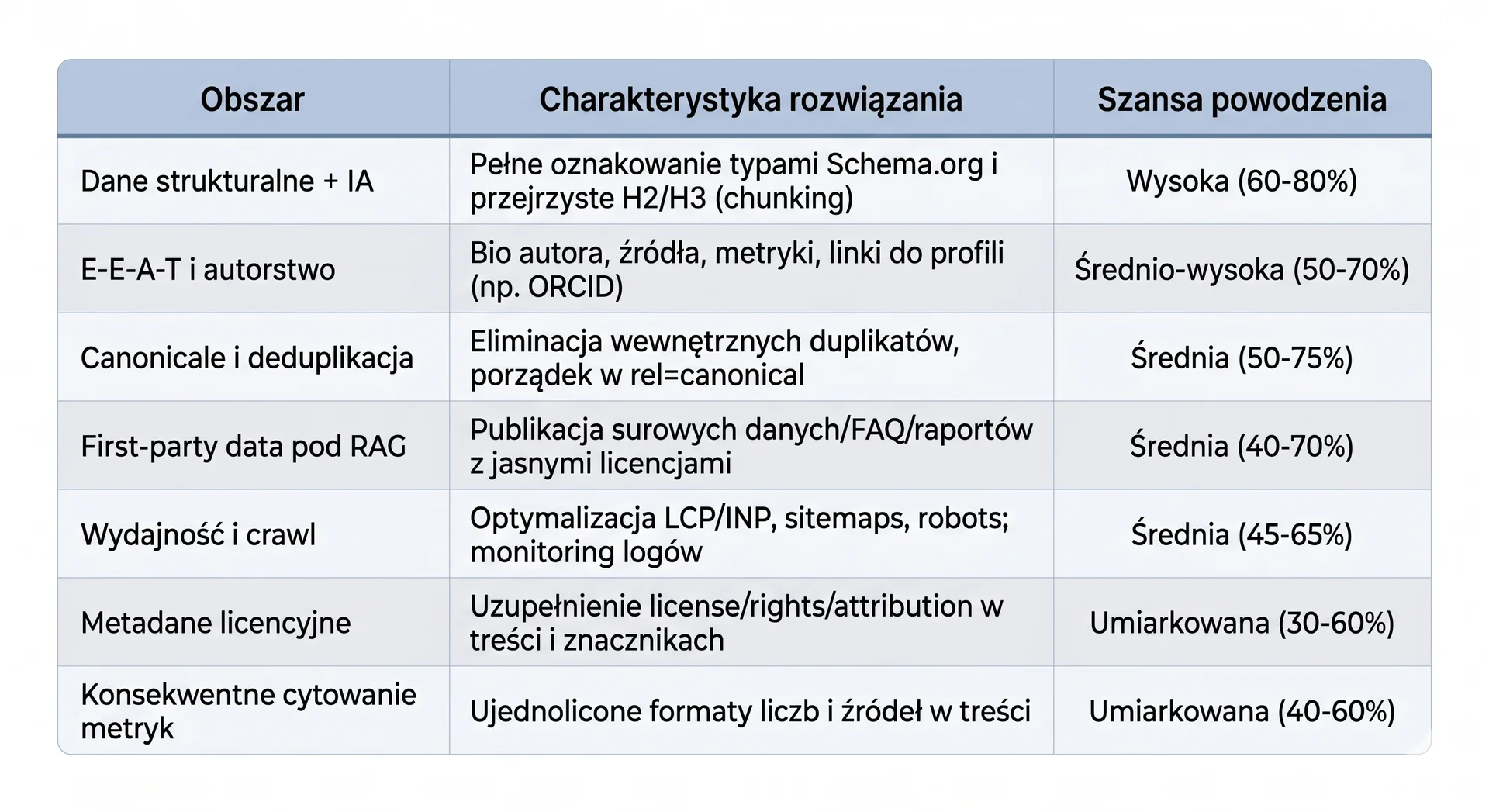
Na co zwrócić uwagę?
Poniżej zestawiam najczęstsze rozwiązania, ich charakterystykę oraz szacowane prawdopodobieństwo powodzenia w horyzoncie 4-8 tygodni. To estymacje operacyjne, a nie gwarancje efektu. W GEO wyniki zależą od klasy zapytań, crawlability, autorytetu domeny, konkurencji i tego, czy model w danym momencie korzysta z web search.
Diagnostyka problemów
Aby odróżnić problemy o podobnych objawach, stosuję ścieżkę diagnostyczną opartą na danych.
Porównaj widoczność i CTR: stabilne pozycje + spadający CTR wskazują na wpływ elementów answer-first, niekoniecznie na spadek rankingów.
Porównaj SERP i LLM: jeżeli domena jest wysoko w Google, ale nie pojawia się w odpowiedziach LLM, problemem może być cytowalność, struktura treści, zewnętrzne potwierdzenia encji albo brak pokrycia pytań fan-out.
Zweryfikuj kanonikale i duplikację: rozjazdy URL-i w indeksie i kanibalizacja tematów sugerują problemy z konsolidacją sygnałów.
Sprawdź logi serwera: skoki ruchu z nieznanych agentów i botów AI mogą wymagać rate-limitingu, cache, WAF, weryfikacji user-agentów i aktualizacji robots.txt.
Audytuj dane strukturalne: brak typów kwalifikowalnych dla rich results koreluje z niższą czytelnością semantyczną i utrudnia maszynowe rozumienie głównej encji.
Oceń E-E-A-T: brak podpisanego autorstwa, źródeł, metodologii i dat aktualizacji zwiększa ryzyko błędnych parafraz.
Przetestuj answer readiness: sprawdź, czy pierwsze 150-250 słów odpowiada na główne pytanie, czy definicje są jednoznaczne, a sekcje mają własny kontekst.
Porównaj odpowiedzi modeli: ChatGPT, Claude, Gemini, Perplexity, Copilot i AI Overviews mogą cytować różne źródła, więc pojedynczy test nie jest reprezentatywny.
Mierz stabilność: Authoritas w badaniu zmienności SERP wskazywał, że w okresie 2-3 miesięcy około 70% stron rankujących w AI Overviews może się zmienić, dlatego pomiar powinien być cykliczny, nie jednorazowy.
Wzrost udziału nieznanych agentów w ruchu to realny koszt, który wpływa na budżet crawl i obciążenie infrastruktury. Wydawcy i właściciele serwisów coraz częściej potrzebują polityki dostępu dla AI crawlerów: co wolno indeksować, co wolno wykorzystywać do treningu, co powinno być dostępne dla user-triggered fetch, a co wymaga blokady lub limitu. Cloudflare wprowadził narzędzia, które pozwalają audytować i kontrolować dostęp modeli AI do treści serwisu. To pokazuje, że warstwa infrastrukturalna staje się częścią strategii GEO.
Monitoring AI
W praktyce monitoring GEO powinien obejmować minimum pięć metryk.
LLM Visibility
Odsetek zapytań fan-out, w których marka lub domena pojawia się w odpowiedzi. Niska wartość oznacza, że marka nie jest rozpoznawana jako źródło w kategorii.Traffic AI
Ruch pochodzący bezpośrednio z odpowiedzi generowanych przez modele LLM. Nie cały ruch jest obecnie tagowany i możliwy do rozpoznania. Warto jednak śledzić trend.Stability
Spójność obecności między modelami i kolejnymi pomiarami. Niska stabilność oznacza, że wynik może być przypadkowy lub zależny od snapshotu.SERP vs LLM Gap
Różnica między widocznością w klasycznym SERP a obecnością w odpowiedziach AI. Duża luka wskazuje na problem cytowalności, encji, zewnętrznych potwierdzeń albo struktury treści.
Zespół powinien działać w iteracjach: od diagnozy, przez wdrożenia, po monitoring skutków. Optymalizacja pod AI nie zastępuje SEO. Rozszerza je o retrievability, cytowalność, entity coverage, weryfikowalność claimów i mierzenie obecności w odpowiedziach. Najbardziej odporna strategia łączy trzy warstwy: techniczne dopuszczenie do indeksu i snippetów, treść gotową do cytowania oraz zewnętrzne potwierdzenia autorytetu marki.
Podsumowanie
Na koniec warto pamiętać o najprostszej zasadzie: twórz treści dla ludzi i jasno opisuj je dla systemów, które mają je zrozumieć. W GEO najlepszy efekt dają materiały, które jednocześnie spełniają intencję użytkownika, mają jasno opisane encje, zawierają weryfikowalne claimy, podają źródła przy konkretnych twierdzeniach i są technicznie dostępne dla wyszukiwarek oraz systemów AI. To fundament, na którym modele generatywne najłatwiej rozpoznają wartość, kontekst i możliwość bezpiecznego cytowania.
FAQ: optymalizacja pod AI
Jak szybko zobaczę efekt wdrożenia danych strukturalnych?
Pierwsze zmiany w rich results mogą pojawić się po recrawlu i reindeksacji, ale Google nie gwarantuje wyświetlenia rich result nawet przy poprawnym markupie. W praktyce efekty CTR najczęściej oceniam po 2-4 tygodniach, a wpływ na cytowania AI po 4-8 tygodniach, przy założeniu że strona jest indeksowalna i ma popyt na zapytania.
Czy autorstwo realnie wpływa na cytowanie przez modele?
Tak, ale nie jako sam podpis autora. Znaczenie ma cały zestaw dowodów: bio, doświadczenie, profil autora, data aktualizacji, źródła, metodologia i spójność z danymi organizacji. E-E-A-T w GEO działa najlepiej wtedy, gdy jest widoczne zarówno dla użytkownika, jak i dla parsera.
Co, jeśli treść jest często parafrazowana błędnie?
Warto ujednolicić metryki i źródła, uporządkować kanonikale, skrócić kluczowe akapity do cytowalnych bloków i podlinkować źródło przy konkretnym twierdzeniu. Pomaga też sekcja „Najważniejszy wniosek” oraz tabela z danymi, bo modele łatwiej wyciągają stabilne informacje z wyraźnych struktur.
Czy warto tworzyć dedykowane treści pod RAG?
Tak, szczególnie zestawy danych, FAQ, raporty, metodologie, porównania i aktualizowane przewodniki z jasną licencją i atrybucją. Nie powinny to być jednak strony tworzone wyłącznie „pod model”. Muszą odpowiadać na realną intencję użytkownika i wnosić information gain względem konkurencyjnych źródeł.
Czy blokować boty AI w robots.txt?
Nie ma jednej odpowiedzi. Blokady mogą zmniejszyć koszty crawlowania i ograniczyć wykorzystanie treści, ale mogą też zmniejszyć szansę na obecność w wybranych systemach odpowiedzi. Dlatego decyzję warto podzielić według typu bota: trening, indeksowanie/search, user-triggered fetch i klasyczny search crawler.
Czy llms.txt jest obowiązkowy?
Nie. Może być użyteczny jako dodatkowy manifest dla modeli lub agentów, ale nie zastępuje indeksowalności, robots.txt, sitemap, canonicali, danych strukturalnych ani treści widocznej w HTML. W optymalizacji pod Google AI Overviews kluczowe pozostają fundamenty Search i kwalifikowalność do snippetów.
Czy wystarczy dodać FAQ?
Nie. FAQ pomaga tylko wtedy, gdy odpowiada na realne pytania użytkowników, jest widoczne w treści, nie powiela sztucznie całego artykułu i zawiera precyzyjne odpowiedzi. Dla GEO lepsze są krótkie, źródłowane odpowiedzi niż długie bloki ogólników.
Jak mierzyć, czy GEO działa?
Mierz nie tylko ruch organiczny, ale też cytowania, wzmianki, klasy obecności, liczbę unikalnych cytowanych URL-i, overlap SERP vs LLM, stabilność między modelami oraz zmiany CTR na frazach z AI Overview. Bing zaczął udostępniać w Webmaster Tools panel AI Performance, który pokazuje m.in. liczbę cytowań, cytowane URL-e, grounding queries i trendy widoczności w AI answers.